Cross-post from: http://idibon.com/ai-for-world-scale-data-on-a-laptop/
Idibon is announcing the launch of a new Machine Learning library, IdiML, for ultra-low latency text analytics at scale.
Artificial Intelligence has become common in business, especially in big data processing. For most companies, it has simply been impossible to process the amount of data produced by large scale text processes like social media services, or to apply fast machine learning for real-time human interaction. We are aiming to solve this for everyone.
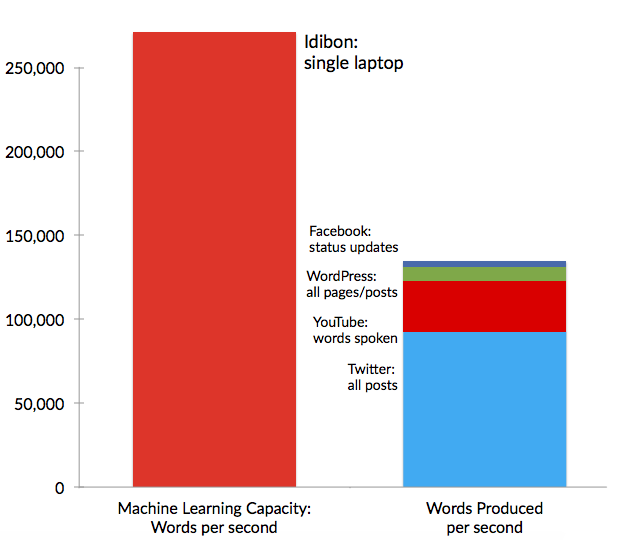
IdiML is so fast, you can process the entire Twitter Firehose in real-time on the CPU of a single laptop, still leaving half the CPU capacity free!
In fact, that’s exactly what we did for one benchmark: we ran volumes of real-time data equal to the firehoses of the major social media companies on a single laptop, extracting insights from every communication. Within Idibon, this has been the work of the ‘IdiML Team’, who have collectively been optimizing the entire machine learning pipeline within our Idibon Terminal product. Our cloud-based services are many times faster than a single laptop, but for simplicity we’ll just share the single-laptop benchmarks.

Part of the IdiML Team: Haley Most, Gary King, Michelle Casbon and Nick Gaylord, with Idibon CEO Robert Munro, center, holding a laptop that can now easily process the largest text firehoses (not pictured but also vital to IdiML: Stefan Krawczyk and Paul Tepper)
On a single laptop, you could also process every Facebook status update, every transcribed word from YouTube videos, and every word on every single WordPress blog, extracting tailored categories of information about sentiment, topics or intents. (For the tech-minded, this benchmark was set on a standard 16gb MacBook Pro, over millions of tweets with duplicates and retweets removed, with less than 5% standard deviation across successive runs*).
The breakthrough comes from intelligent in-memory processing that allows the information to be extracted without expensive database or file lookups. IdiML intelligently pre-compiles information from deep-learning, feature extraction, and client-defined semantic libraries, making the knowledge highly available through compression and in-memory data structures. At the point of processing, this allows a minimum number of passes to be made over the text, with our artificial intelligence extracting information continuously over the stream of data at breakneck speeds.
This means we achieve insights in microseconds. Many systems, like the SparkML library that we extended in the course of this work, only permit batch processing. For example, many systems only scale by processing 10,000s of documents together, waiting for 10,000 to come in, and sending them all off to be processed and returned later. Even modern data processing platforms like Hadoop and Spark have this limitation. For some of our competitors, this means many seconds, minutes, or even hours before insights are returned. For Idibon, we’re not disguising our capacity figures: the average document size for our tests was just 9 words, and we posted each document to our API individually, meaning that we made more than 30,000 consecutive calls to Idibon Terminal per second, with an average turnaround of just 120 microseconds!
Idibon was already the leading company for combining human and machine intelligence. Our off-the-shelf services like sentiment analysis are industry-leading at around 75% accuracy, but the real power comes in our ability to intelligently incorporate human feedback to reach 90% accuracy and adapt the machine learning to our clients’ specific information extraction requirements. For users of Idibon Studio and Idibon Terminal, this will mean that our solutions will adapt to your specific categories faster and enable you to deploy smart, automated processing over even more data.
For popular tasks like sentiment analysis, we will let everyone take advantage of IdiML for free. Anyone who is benefiting from our free Idibon Public solution will have the IdiML extensions available in future releases, allowing everyone to process data at scale locally. We will also continue to contribute to Spark’s open source libraries, allowing software developers to benefit across the world. This is our first release of new benchmark data, but you you can see Michelle Casbon discussing the idiML innovations in this video from a recent Spark meetup: https://www.youtube.com/watch?v=T3RjQ0hZgk8
And just like all our other work, our new extensions are language independent. The new IdiML is compatible with the 60+ languages that we have worked in to date and any that we will add. Idibon was formed with the goal of bringing intelligent language processing to all the world’s languages, and the IdiML breakthrough takes us one step closer.
Robert Munro
February, 2016
* The benchmark was set on 16gb MacBook Pro running OS X Yosemite 10.10.2, over millions of tweets with duplicates and retweets removed to ensure variety. We ran multiple tests over different sets of data, and found less than 5% standard deviation across successive runs. The speed was about 2x faster when we used raw data that included duplicates and retweets, thanks to our caching strategies, so our speeds “in the wild” are likely to even faster than our benchmarks.
** The sources for the volume of Twitter, Facebook, YouTube and WordPress volumes comes from Twitter, KissMetrics, Google and TorqueMaq.
June 3rd, 2016 at 9:51 pm
[…] human users. On the deployment side, it was a joy to see our team give an already well-engineered machine learning library within Spark a 40x speed up, open-sourcing the innovation so that engineers everywhere can take advantage of low latency […]
June 3rd, 2016 at 9:52 pm
[…] human users. On the deployment side, it was a joy to see our team give an already well-engineered machine learning library within Spark a 40x speed up, open-sourcing the innovation so that engineers everywhere can take advantage of low latency […]